

Welcome to Part 2 of SQL Server Backup Internals. This blog series is a companion piece to my How to Accelerate Your Database Backups for MSSQLTips.com. In Part 1 of this blog series, I introduced the parts of a BACKUP operation.
Blog Series Tables of Contents
Now let’s start focusing on performance characteristics. We can impact the performance of a BACKUP operation by making changes to or more of the following:
- Increase the Number of Backup Buffers
- Increase the Size of Backup Buffers
- Add more CPU Reader Threads
- Add more CPU Writer Thread
Analogy Time!
I like to explain things with silly analogies and today will be no exception. Today, let’s pretend that we are in a shipping warehouse.
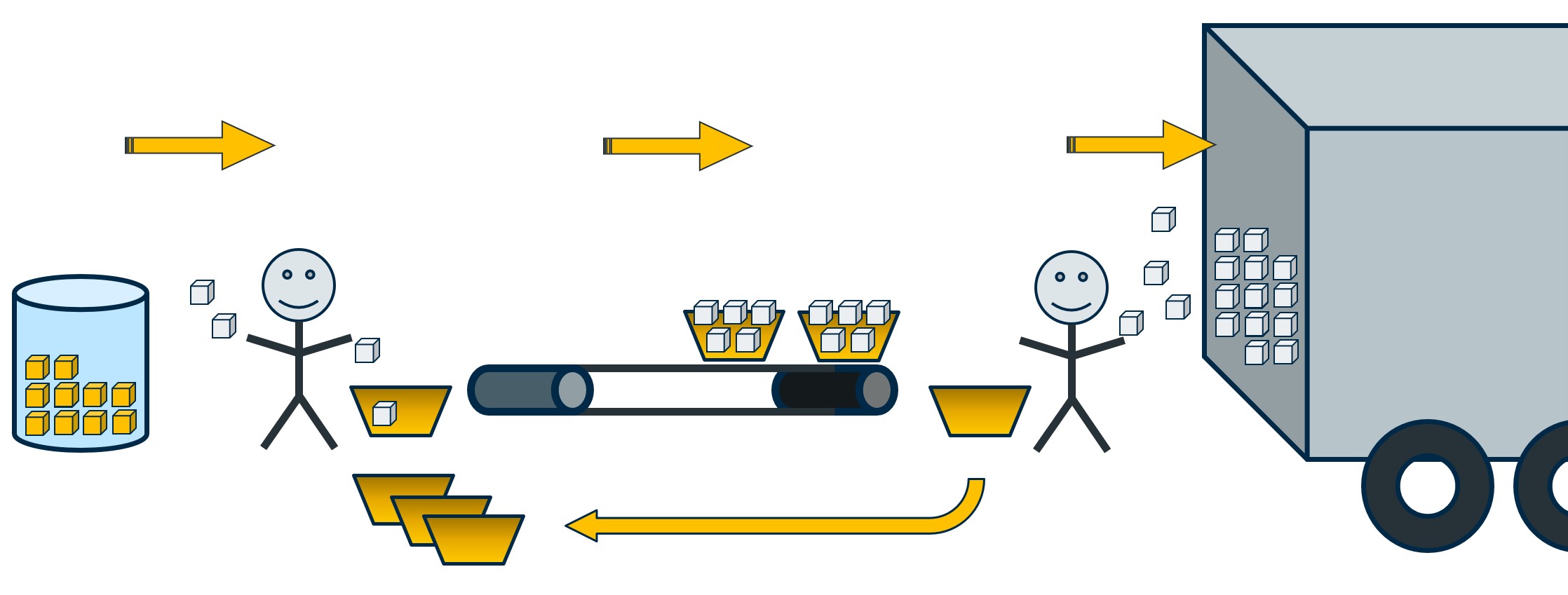
The person on the left “reads” the contents of the main container and makes copies of each widget, tossing as many widgets as they can into an available yellow basket. When the basket is full, it is sent to the other employee, who takes the contents of each basket and places it into the truck. And they also return the basket back to the first employee to be refilled.
In this silly analogy, the left employee represents a single CPU Reader Thread. They are copying data pages out of a database file and placing them into a yellow basket, which represents a backup buffer. The stack of empty yellow baskets represents the other backup buffers waiting to be filled in the Free Queue. Once a basket is filled, it is sent over to the Data Queue, which the other employee picks up one by one. That employee takes the contents of the basket and loads it into the truck. This is analogous to a CPU Writer Thread consuming a backup buffer and writing out to the backup target.
Note: The duration of transferring backup buffers from one queue to another is effectively nil. “Transfer” is probably not the best word choice here as I don’t believe any actual data movement occurs.
Backup Buffers
To help accelerate our backup operations, we can make two adjustments to our backup buffers – adding more backup buffers and increasing the size of the backup buffers.
Add More Baskets
First, let’s explore adding additional backup buffers. That’d be like having more than seven baskets to pass blocks back and forth in the diagram above. In a perfect system, both employees would be processing baskets at perfectly equal speeds. But the real world isn’t perfect – one employee may be much faster than the other.
Scenario 1
Let’s pretend the first employee is the slower one. They can fill a basket at a rate of 1 basket every 10 seconds. The second employee can process a basket at a rate of 1 every 5 seconds. So when they begin work, the second employee is sitting idle waiting for a basket to arrive. It is able to process the received basket quickly, pass it back, then sits and waits for the first employee to complete filling another basket.
Scenario 2
Conversely, if the first employee can fill a basket at a rate of 1 per second, they’ll have sent all 7 available baskets to the other employee after 7 seconds. The second employee still takes 5 seconds to process a filled basket, but the first employee will have to wait 4 seconds between receiving free baskets after they get going. The second employee now has a backlog of baskets to process because it is much slower than the first employee.
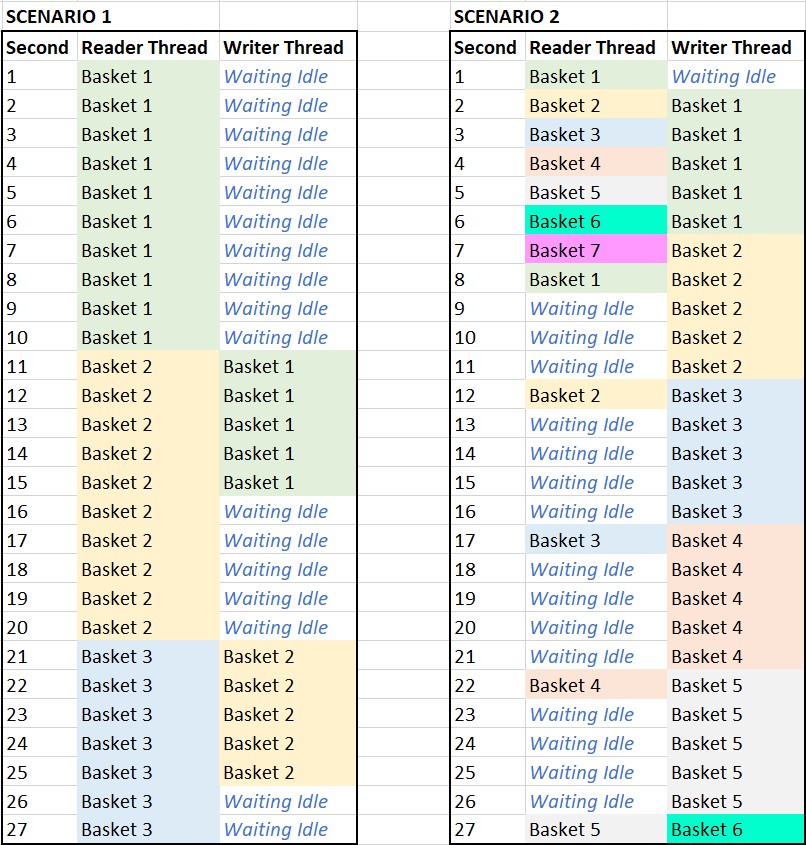
Check out the time lapse chart. One thing that is very clear is that due to the different processing rates, either the Reader or Writer will incur some idle time. Imagine what this might look like if the number of buckets was larger or smaller? And imagine what this might look like if the processing rates were orders of magnitude different?
Use Bigger Baskets
The other adjustment that can be made is to make each basket bigger. Depending on the rate of filling or processing a basket, making all baskets larger can increase overall throughput of the process. If we doubled the size of the basket, the fill rate and process rate would still increase proportionally. So in the first scenario above, the fill rate would be 1 basket every 20 seconds and the processing rate would be 1 basket every 10 seconds. And the second scenario, we’d see a fill rate of 1 basket every 2 seconds and a processing rate of 1 basket every 10 seconds.
Are you seeing a bit of a “so what’s the benefit, why bother?” conundrum here? Hold that thought for a bit.
What Are the T-SQL Parameters?
Skipped over the analogy to the good stuff? Here you go:
- BUFFERCOUNT (BC) – Define the number of Backup Buffers to be used
- MAXTRANSFERSIZE (MTS) – Define the size of each Backup Buffer
MAXTRANSFERSIZE can range anywhere from 64KB to 4MB. Frankly, I’m not sure what the allowed range of values is for BUFFERCOUNT. But because of the workflow above, there is a point where having too many Backup Buffers are a waste, because neither side can fill or process them fast enough.
Additionally, there’s a resource price to pay in the form of RAM consumed. Very simply, your BACKUP operation will consume BUFFERCOUNT * MAXTRANSFERSIZE in RAM. So if you run a BACKUP with BUFFERCOUNT = 10 and MAXTRANSFERSIZE = 1MB, your operation will consume 10MB of RAM. But if you crank things up, BUFFERCOUNT = 100 and MAXTRANSFERSIZE = 4MB, that’s now 400MB of RAM for your operation.
What about the existing SQL Server Buffer Pool? Backup Buffers are allocated outside of buffer pool memory. If you don’t have enough RAM available, SQL Server will shrink the buffer pool as needed to accommodate your backup buffer requirement. (I plan to talk about overall resource balancing in a future part of this series.)
What’s the Benefit?
So what’s the overall benefit of messing with these two parameters. If one is solely leveraging these two parameters and no other adjustments, not much really. The main bottleneck your BACKUP operation will experience is due to only having 1 Reader and 1 Writer thread. So adding a few more Backup Buffers can help your overall performance a bit, but as you saw with the time lapse examples, if you have different processing rates on one side or the other, the extra backup buffers don’t really help – they’ll just sit in one of the queues waiting on the CPU threads.
It is far more beneficial to make adjustments to BUFFERCOUNT and MAXTRANSFERSIZE if you also make adjustments to the number of Reader and/or Writer threads for your BACKUP operation. And that’s what I’ll be covering in Part 3 of this series, so stay tuned! Thanks for reading!

Hi Andy,
Nice series. You know. I loved to geek out in this area, so make sure you specify that this explanation is for Full rather than diff or log backups which work very differently.
You may also want to add a bit about which memory cache this is allocated from. I know it swapped some time back but some folks will have old versions kicking around so important to point out.
LRD
Great feedback LRD, thank you! I’ll make some adjustments accordingly.
And great to hear from you. 🙂