

Recently, I had the pleasure of delivering a new presentation called How to Accelerate Your Database Backups for MSSQLTips.com. This blog series is intended to be a companion piece, particularly for those who prefer to read content instead of watching a video. And this series is focused exclusively on FULL BACKUP operations. I might talk DIFFs and LOG BACKUPs another time.
They Just Work
For many of us, native BACKUPs on SQL Server “just work.” Many are content to use BACKUP with defaults and as long as errors aren’t thrown, don’t think much beyond that. But not all of us have the luxury of adequate BACKUP maintenance windows, especially when faced with the ever-growing sizes of our databases.
So to speed up our BACKUP operations, we turn to using backup compression, backup file striping, and two parameters: BUFFERCOUNT and MAXTRANSFERSIZE. Many have been blogging about these four things for many years now. But what I find interesting is that very few of those blogs have really explored WHY each brings a performance benefit for BACKUP operations.
That ends to today.
But How Do They Work?
In the simplest example, a BACKUP operation has the following players:
- a database source volume
- a backup output file
- a reader thread
- a writer thread
- a set of backup memory buffers
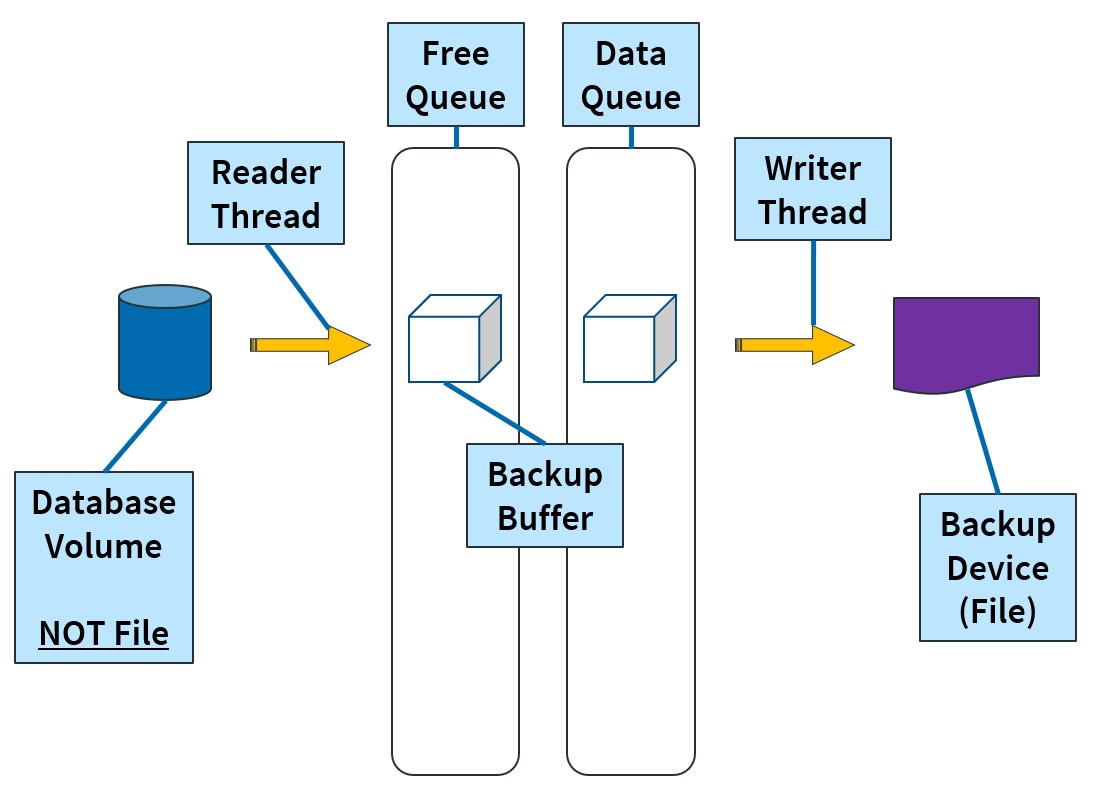
Here is the basic flow of a BACKUP operation:
- The Reader Thread will read data from a database file, into an empty Backup Buffer in the Free Queue.
- Once the Backup Buffer is full, it will be moved into the Data Queue.
- The Reader Thread will start filling up another Backup Buffer in the Free Queue (if available), otherwise it must wait until the Free Queue has an empty Backup Buffer available.
- The Writer Thread monitors the Data Queue and once it sees that a filled Backup Buffer has entered the Data Queue, it will transfer the contents to a Backup Device.
- Once the Backup Buffer is emptied, it is moved back to the Free Queue to be populated again by the Reader Thread.
When you run a basic BACKUP command without any optional parameters, you will always get 1 reader thread and 1 writer thread. The number of Backup Buffers varies depending on the Backup Device type (DISK, URL, TAPE). The most commonly used is DISK, which will get 7 Backup Buffers, each Buffer being 1MB in size.
Low Overhead
It’s interesting to note that BACKUP’s resource utilization is relatively low. A BACKUP to DISK with no optional parameters operation requires 2 CPU threads (1 Reader, 1 Writer), and 7MB of RAM (7 Backup Buffers, 1MB each). My understanding is that this was architected this way intentionally, long ago when production servers were less powerful than my smartphone, to ensure that a BACKUP operation has minimal impact when running.
Give Me More Power!
As data can be moved between 1 Reader, 7 Backup Buffers, and 1 Writer, BACKUP can be rather slow. And these days, our databases are terabytes in size, with limited maintenance windows to complete them. Thankfully, we have a number of different parameters that will allow us to increase the horsepower behind a BACKUP operation, which I’ll write in Part 2 of this BACKUP Internal series!
So stay tuned for Part 2 and thanks for reading!

Nice…. Looking forward to the rest of this series. Thanks, Andy.