

Welcome back to Part 3 of my SQL Server Backup Internals Series.
In Part 1, I introduced the “parts” of a BACKUP Operation and in Part 2, we delved into Backup Buffers. Today, we’re going to talk about what manipulates those Backup Buffers = CPU Threads. This’ll be a longer blog, so go refill your coffee now.
Many Hands Make Light Work
Let’s start by returning to our analogy. We’ve called in some friends to help out. First, what happens if we have all of our extra help on the Reader side loading Backup Buffers?
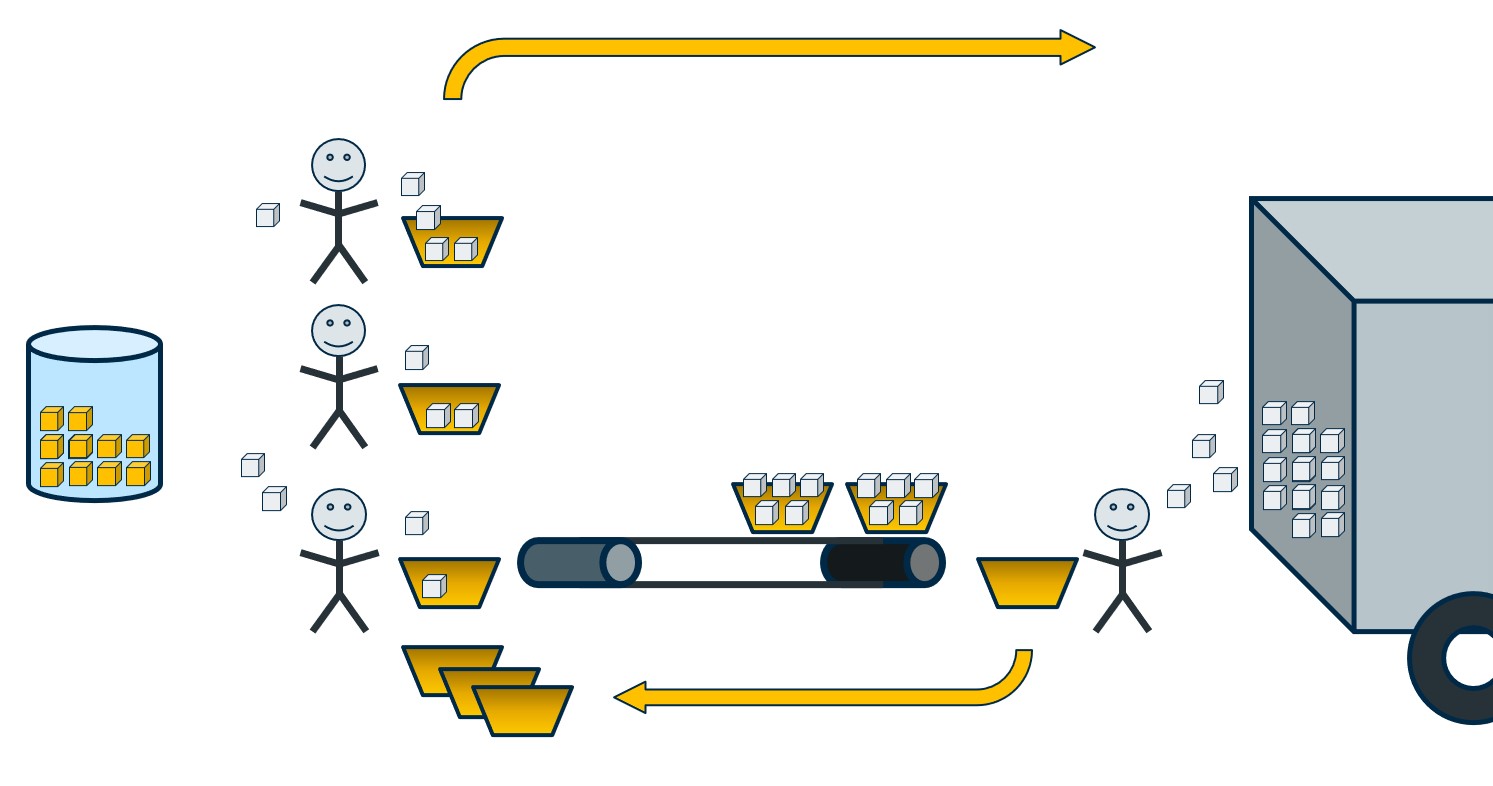
Assume that each worker processes widgets at the same rate of 1 per second. So each second that passes, 3 Reader workers are copying widgets into baskets. But our lone Writer worker can only process at a rate of 1 widget per second. So the Writer worker will be overwhelmed very quickly as more baskets are sent by the Reader workers. If the Writer worker happens to be much faster, say able to process at a rate of 30 widgets a second, then that worker can easily keep up with everything that the 3 Reader workers send over.
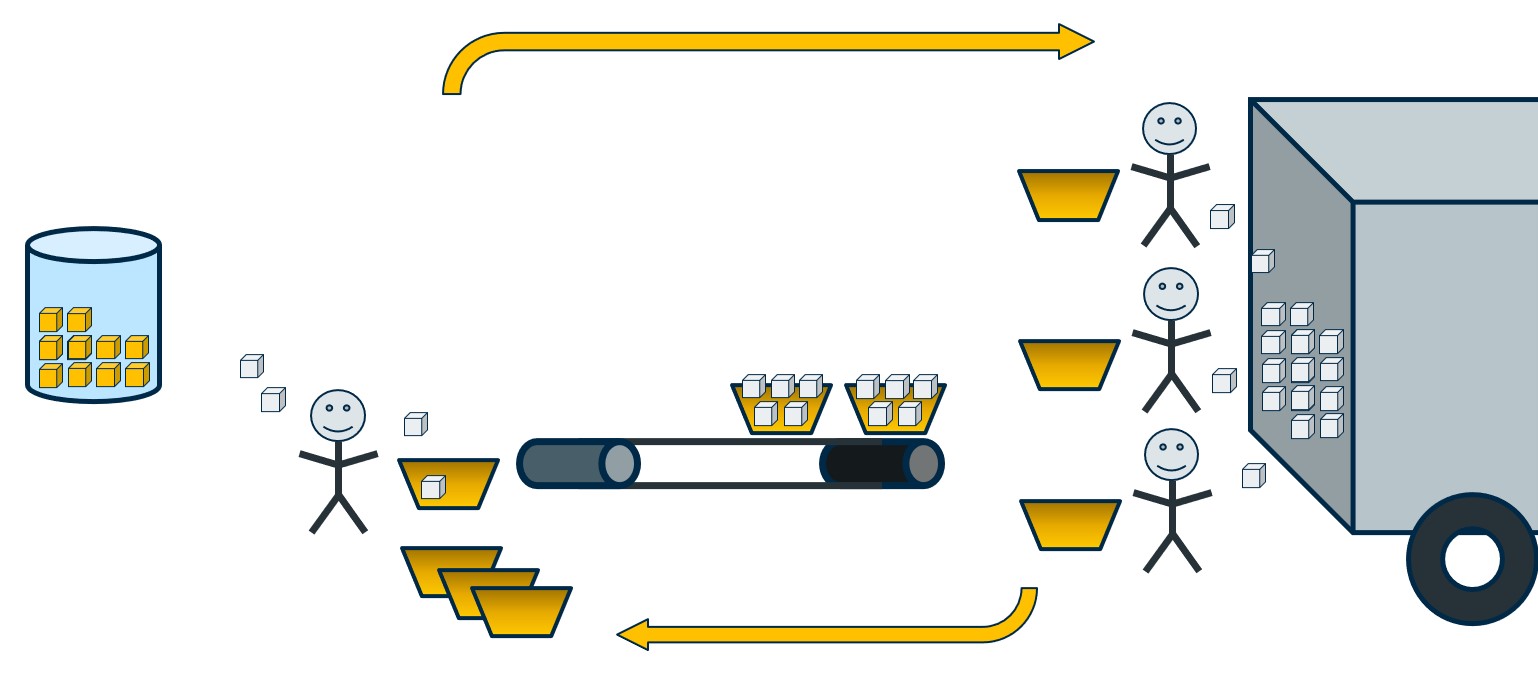
Alternatively, let’s shift our extra workers to help out on the Writer side. If our Reader worker can process at a rate of 3 widgets a second, and each Writer worker processes at a rate of 1 widget a second, we’ll have a processing balance on both sides, thus maximizing our throughput potential.
But like before, if processing rates differ, a bottleneck may occur. If our single Reader worker only processes at a rate of 1 widget a second, they will not be able to fill up baskets as fast as the three Writer workers can process them (a total of 3 widgets per second). This imbalance will result in Writer workers sitting idle and waiting.
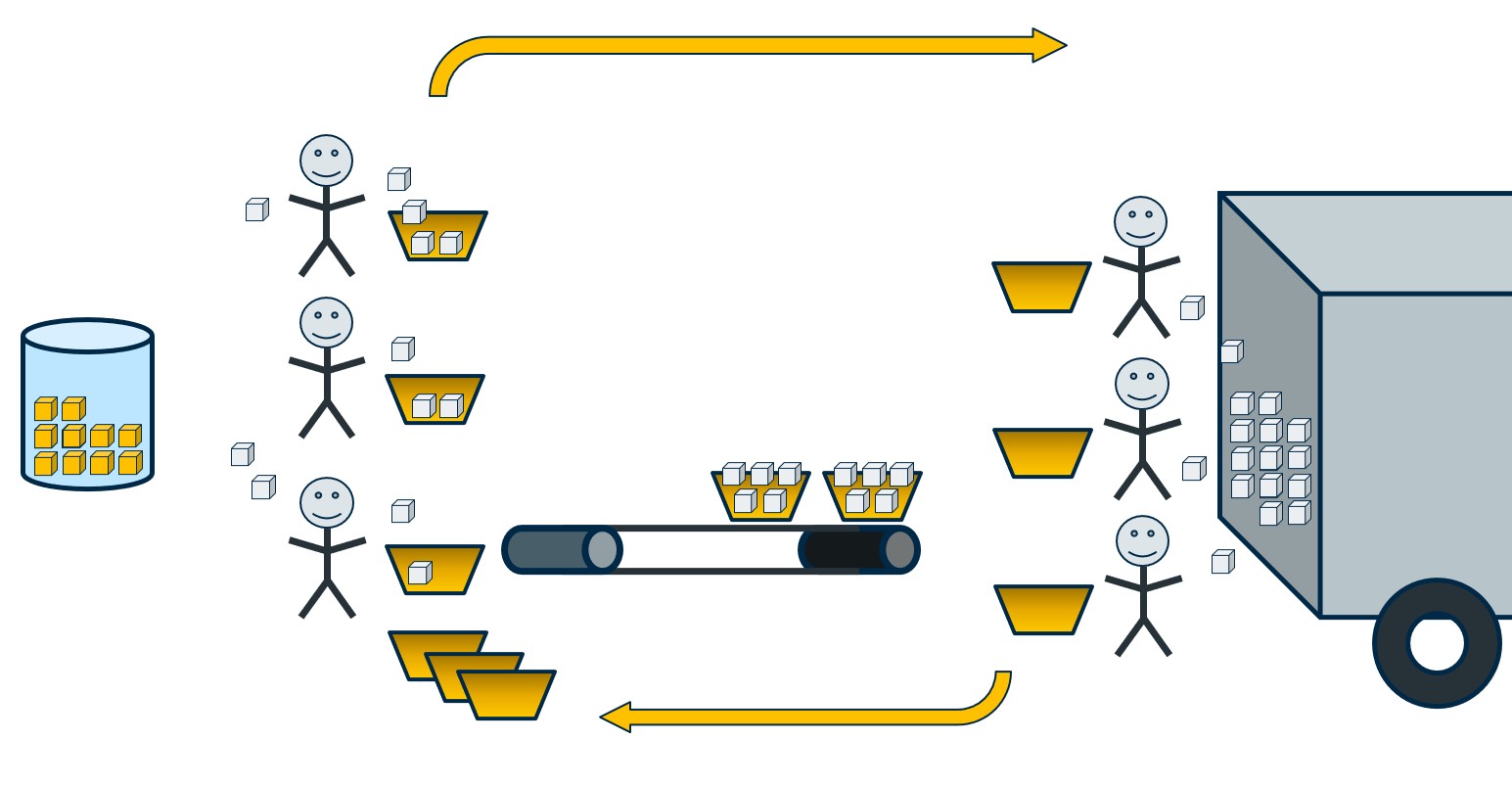
In an ideal situation, one would add more Readers and Writers, and supply enough baskets to the entire workflow. We want a balance where both Readers and Writers are always working, regardless of individual worker processing rate differences. Ideally, no one is ever waiting for a basket.
Adding More Reader Threads to BACKUP Operations
Okay, you jumped ahead to find out how to add additional Reader threads to your BACKUP operations. Unfortunately, the answer is a bit tricky. The number of Reader threads a BACKUP operation is tied to the number of database volumes that a given database exists on. It is critical to note that this is not synonymous with the number of data files, though you obviously need multiple data files in order for a database to be able to span multiple volumes.
In Windows, a common setup is each storage volume (aka Disk) that is presented to a server has its full capacity partitioned as a simple volume and mapped to a drive letter.
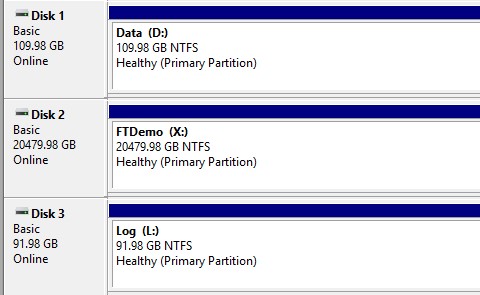
Now let’s say I have a database with multiple data files, and all of the data files reside on a single Windows Drive – also a common arrangement.

If I execute a BACKUP operation, no matter what parameters I use, my BACKUP operation will only ever get 1 Reader Thread.
That’s it.
If you want MORE Reader threads, you’ll need to spread your data files across multiple Windows volumes.


In this example, the Sandbox_MultiVol database has 3 data files spread across 3 different Windows Drives – M:, N:, and O:. As a result, any BACKUP operation on this database will get 3 Reader threads.
Edge Case – Multiple Windows Volumes on a Single Disk
There’s also uncommon cases when one might take a Disk (Storage Volume) presented to Windows and partition it into multiple simple volumes.



For these two examples, do you think a BACKUP operation against either of these databases will get 1 Reader thread or 3 ?
In both cases, you’ll get 3 Reader threads.
The code behind BACKUP is tied to the volumes visible to Windows. I’ll confess that before I tested this, I theorized that the BACKUP operation would associate with the physical storage presented, thus granting only get one Reader thread.
Adding More Reader Threads – TL;DR
Unless you want to go to the hassle of carving up your database into multiple data files, adding more Windows volumes, and moving your data files across multiple Windows volumes, you cannot add additional Reader threads to your BACKUP operations.
Adding More Writer Threads – aka Backup Striping
Thankfully adding more Writer threads is much easier. That is tied to the number of backup devices that you specify in your BACKUP command.
-- Syntax:
BACKUP sandbox TO
<backup_device> [ ,...n ]
-- 1 backup_device on 1 Windows volume
-- this will yield 1 Writer threads
BACKUP sandbox TO
DISK = 'S:\backups\sandbox-1.bak';
-- 4 backup_devices on 1 Windows volume
-- this will yield 4 Writer threads
BACKUP sandbox TO
DISK = 'S:\backups\sandbox-1.bak',
DISK = 'S:\backups\sandbox-2.bak',
DISK = 'S:\backups\sandbox-3.bak',
DISK = 'S:\backups\sandbox-4.bak';
-- 4 backup_devices across 2 Windows volumes (S:, T:)
-- this will also yield 4 Writer threads
BACKUP sandbox TO
DISK = 'S:\backups\sandbox-1.bak',
DISK = 'S:\backups\sandbox-2.bak',
DISK = 'T:\backups\sandbox-3.bak',
DISK = 'T:\backups\sandbox-4.bak';More Examples
Example 1 – Sandbox_MultiVol

-- 3 Reader Threads, 1 Writer Threads
BACKUP Sandbox_MultiVol TO
DISK = 'S:\backups\Sandbox_MultiVol-1.bak';
-- 3 Reader Threads, 4 Writer Threads
BACKUP Sandbox_MultiVol TO
DISK = 'S:\backups\Sandbox_MultiVol-1.bak',
DISK = 'S:\backups\Sandbox_MultiVol-2.bak',
DISK = 'S:\backups\Sandbox_MultiVol-3.bak',
DISK = 'S:\backups\Sandbox_MultiVol-4.bak';Example 2 – Sandbox_SingleVol

-- 1 Reader Threads, 1 Writer Threads
BACKUP Sandbox_SingleVol TO
DISK = 'S:\backups\Sandbox_SingleVol-1.bak';
-- 1 Reader Threads, 4 Writer Threads
BACKUP Sandbox_SingleVol TO
DISK = 'S:\backups\Sandbox_SingleVol-1.bak',
DISK = 'S:\backups\Sandbox_SingleVol-2.bak',
DISK = 'S:\backups\Sandbox_SingleVol-3.bak',
DISK = 'S:\backups\Sandbox_SingleVol-4.bak';In Conclusion
Now you should have a solid understanding of how BACKUP operations can get more Reader and/or Writer threads allocated. Stay tuned for Part 4 where I’ll dive into the topic of BACKUP compression, then Part 5 where I’ll explore balancing all of these tuneables to maximize performance.
Thanks for reading!

3 thoughts on “Backup Internals – Part 3: CPU Threads”