Welcome back to another quick blog, about something I just learned about.
Am playing around with Always Encrypted for the first time. I was just following along the basic tutorial and encrypted some columns in my AutoDealershipDemo database. But then I decided to go crack open the data page using my friend DBCC PAGE.
Text output of DBCC PAGE (15, 1, 1218323, 3)
WITH TABLERESULTS
Because I only ever use DBCC PAGE() once every so often, I did a quick search to refresh on the syntax. And what I found was someone who used something I’d never seen before…
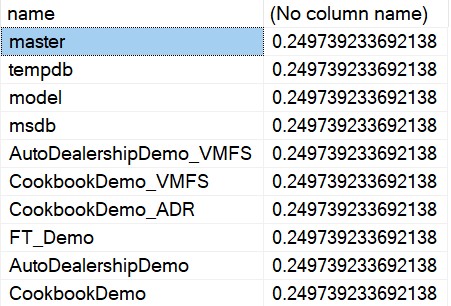
DBCC PAGE(aa, bb, cc, dd) WITH TABLERESULTS
“WITH TABLERESULTS”? What is this…?
DBCC PAGE(15, 1, 1218323, 3) WITH TABLERESULTS
WOW – for me, this makes the output SO much easier to consume!!!
And what of that encrypted data?
And if you’re curious, here’s what I was really after.
See how I had encrypted the VIN, InvoicePrice, MSRP, and DateReceived columns in my test table. Pretty cool to see it scrambled up and interesting to see how it consumed a heck of a lot more space in-row.
DBCC Commands
Another quick search tells me that you can also use “WITH TABLERESULTS” with other DBCC commands too. I didn’t look much more into it since I got what I wanted, but thought I’d share this neat tidbit.
Found an interesting tidbit while working on a compression diagnostic script, and thought I’d write a quick blog.
Was refreshing myself on all of the output of sys.dm_db_index_physical_stats and the nuances, when I found an interesting tidbit about “compressed_page_count.”
For heaps, newly allocated pages aren’t PAGE compressed.
A heap is PAGE compressed under two special conditions: when data is bulk imported or when a heap is rebuilt. Typical DML operations that cause page allocations aren’t PAGE compressed.
Rebuild a heap when the compressed_page_count value grows larger than the threshold you want.
Well then… moral of the story folks, is that if you have heaps that are PAGE compressed, you may not be getting the benefits you think you’re getting if you’re not executing rebuilds regularly!
Recently someone asked my wife Deborah if she knew if my sp_helpExpandView utility procedure could also work with triggers. Great question – I rarely work with triggers, especially nowadays, so I had no idea… and finally found some time and motivation to dig into it deeper.
TL;DR – How Does sp_helpExpandView Work with Triggers?
If you run sp_helpExpandView whose parameter IS a trigger, you’ll get information about the objects that the trigger references. However, you will not get information about the table that the trigger is associated with (which could be derived from another query).
If you run sp_helpExpandView whose parameter is a table that HAS a trigger, you will NOT get any information about that trigger being present. You’ll have to write a different query for that.
If you run sp_helpExpandView whose parameter is a table that is UTILIZED BY a trigger, you WILL get information about that trigger.
Digging Deeper
To dig deeper, I set up a quick prototype with two tables and a basic INSERT trigger.
USE TempDB;
GO
CREATE TABLE dbo.TableWithADMLTrigger (
RecID INT IDENTITY(1, 1) PRIMARY KEY CLUSTERED,
MyValue VARCHAR(50),
MyTimestamp DATETIME DEFAULT(GETDATE())
);
CREATE TABLE dbo.TriggerAuditTable (
RecID INT IDENTITY(1, 1) PRIMARY KEY CLUSTERED,
InsertedRecID INT,
MyValue VARCHAR(50),
MyTimestamp DATETIME
);
GO
CREATE OR ALTER TRIGGER dbo.tr_InsertTriggerForAuditing
ON dbo.TableWithADMLTrigger
AFTER INSERT
AS
BEGIN
INSERT INTO dbo.TriggerAuditTable (
InsertedRecID, MyValue, MyTimeStamp
)
SELECT inserted.RecID, inserted.MyValue, inserted.MyTimestamp
FROM inserted
END
GO
INSERT INTO dbo.TableWithADMLTrigger (MyValue) VALUES ('alpha');
GO 3
SELECT *
FROM dbo.TableWithADMLTrigger;
SELECT *
FROM dbo.TriggerAuditTable;
GO
Now, let’s try running sp_helpExpandView against each entity.
EXEC sp_helpExpandView 'dbo.TableWithADMLTrigger'; GO
EXEC sp_helpExpandView 'dbo.TriggerAuditTable'; GO
EXEC sp_helpExpandView 'dbo.tr_InsertTriggerForAuditing'; GO
The first two commands will yield nothing. Here’s the output of the third, against the trigger itself. Note that it shows you the dbo.TriggerAuditTable that is used by the trigger, but not the table that the trigger itself is defined on – dbo.TableWithADMLTrigger.
Confused? Me too – which is why I have to re-explain the difference to myself every time I revisit this topic. Hopefully this summary helps you.
Referenced Entities: Return all objects that are referenced by the object parameter passed in.
ex: dbo.MyStoredProcedure that has a SELECT * FROM dbo.MyTable, dbo.MyTable is referenced by the stored procedure and would appear in the resultset from a query against sys.dm_sql_referenced_entities()
Referencing Entities: Returns all objects that are referencing the object parameter passed in.
ex: If dbo.MyTable is passed, then dbo.MyStoredProcedure would appear in the resultset from a query against sys.dm_sql_referencing_entities()
Interestingly enough, not all objects are supported by both DMFs. See the Remarks section of the documentation of either DMF for a full table. But the consequence for sp_helpExpandView is that if you use sp_helpExpandView against tables that are both referenced by or referencing a trigger, it will not yield any output.
Partial Solution via sys.dm_sql_referencing_entities()
You can use sys.dm_sql_referencing_entities() to see triggers that reference a table. Here’s more example code.
SELECT-- DISTINCT
DB_NAME() AS database_name,
@TableName AS table_name,
COALESCE(schemas.name, dm_sql_referencing_entities.referencing_schema_name) + '.' + dm_sql_referencing_entities.referencing_entity_name AS object_referencing_this_table,
COALESCE(schemas.type, NULL) AS referencing_object_type,
dm_sql_referencing_entities.referencing_id AS referencing_object_id
FROM sys.dm_sql_referencing_entities(@TableName, 'OBJECT')
LEFT OUTER JOIN (
SELECT objects.object_id, schemas.name, objects.type
FROM sys.objects
INNER JOIN sys.schemas
ON objects.schema_id = schemas.schema_id
) schemas
ON dm_sql_referencing_entities.referencing_id = schemas.object_id;
You can combine the above plus code that returns all triggers defined on a given table, to give you a bigger picture of trigger impact and relationships. Someday I may try to integrate this into sp_helpExpandView. Or I would absolutely welcome and credit anyone who wants to modify the code and issue a Pull Request on Github.
This is a quick blog to “document” a T-SQL technique for generating random numbers. I’ve been using this for years, but don’t use it frequently enough to have it fully memorized. So whenever I do need it, I must constantly have to go look up whenever I need to use it.
TL;DR
CHECKSUM(NEWID())
SELECT a bunch of Random Numbers
Let’s say you need to generate random numbers as part of a resultset. Here’s a simple example.
/* Use RAND() */ SELECT TOP 10
name,
RAND()
FROM sys.databases;
Unfortunately, if you use RAND(), you’ll get the same value for each record in the resultset. But what if I needed DIFFERENT random values for each record?
There’s a few different approaches you can take but here’s my favorite that I think is the cleanest:
/* Use CHECKSUM(NEWID()) */ SELECT TOP 10
name,
CHECKSUM(NEWID())
FROM sys.databases;
GO 3 -- to loop the prior batch 3 times
Now we get a different random value per record AND different random values per execution!
At this point, you can use whatever other method to limit it down to values that you might want. I use the modulus % operator regularly for this.
/* Generate a random value between 1 and 10 */ SELECT TOP 10
name,
ABS((CHECKSUM(NEWID()) % 10)) + 1
FROM sys.databases;
GO 2
Notice that I added one additional function to the column definition – ABS(). That’s because as you can see in the prior examples, the raw output of CHECKSUM(NEWID()) will return both positive and negative integer values. So if I wanted only positive values between 1 and 10, using ABS() to get the absolute value is a clean solution.
Hope someone else finds this helpful! Thanks for reading.
Welcome back to Part 5 of my Backup Internals Series. In this blog, I want to explore some thoughts around maximizing the performance of your SQL Server backup operations.
Many of us have heard the tidbit that there’s 3 options to any endeavor: Fast, Good, and Cheap, but you can only ever pick 2. When it comes to accelerating your (FULL) backup performance, there’s a similar set of choices you can make, most of which have a trade-off of some sort.
Gather Requirements
If I were to have an opportunity to re-evaluate an environment’s backup strategy and schedule, there’s a number of questions I’d want to try to answer first. Remember, the scope of this thought exercise is thinking about FULL Backup strategy from a purely performance angle.
Questions to Ask
Backup maintenance windows: How long and how frequently? Every night for 4 hours? Anytime over the weekend? For 3 minutes on Sunday, between 22:55 and 22:59?
How many databases to back up and how large are they? Does the server just have 1 database, but it’s 15TB in size? Or do you have 800 databases, one per customer? And of those 800, what’s the individual size distribution? Maybe 700 databases are smaller than 100GB, another 75 databases are between 100GB and 500GB, and the last 25 databases are +500GB?
Exclusivity during backup maintenance window? Do you have the luxury of no workload running during your maintenance window? Or do you also have to juggle index maintenance, DBCC CHECKDB, or other application processes like ETLs, nightly processing jobs, etc.? Or to put it another way, do you have free reign to max out your SQL Server resources during your window?
Assumptions
1 SQL Server with many databases
CPU = 12 cores; RAM = 256GB
Backup storage capacity and storage ingest throughput are not a concern (you bought “orange”)
Will ignore RPO/RTO business priorities (which I might tackle in a future blog)
Start Doing Math
Now that you know how much time you have and how many/how much you need to back up, you need to start weighing your options. Do you have the luxury to run one single backup job that will back up your databases one after another? Or do you need to split your databases across multiple backup jobs that run in parallel?
If server resources were infinite, one could theoretically kick off an individual backup job for each and every database, all starting at the exact same time. But of course, that makes no sense.
Revisiting What We’ve Learned
We now know that if our database’s data file(s) all reside on a single volume, we’ll only ever get one Reader Thread. So with a 12 core server, if I have full usage of the server’s resources, I may start with 8 backup output files to get 8 Writer Threads. And I might choose to use a large BUFFERCOUNT value and larger MAXTRANSFERSIZE value, which will result in more RAM consumption.
Now let’s pretend that to meet our requirements, we need to run backups in parallel. You might estimate that you need to run 4 backup jobs simultaneously. If you use the above parameters, you’ll may now start overrunning your CPU! Remember it’s not always about 100% CPU utilization either… all cores could be utilized at say 30%, but you could be context switching like crazy.
Who Doesn’t Love a Trace Flag?
So of course the above means you need to test different permutations. But when you’re doing testing, how can you determine the actual resource utilization of a given backup job? This is where some infrequently highlighted trace flags come into play.
Trace Flag 3213 - Generate diagnostic data about BACKUP & RESTORE operation (least)
Trace Flag 3004 - Generate diagnostic data about BACKUP & RESTORE operation (more)
Trace Flag 3014 - Generate diagnostic data about BACKUP & RESTORE operation (all) These are officially undocumented
Trace Flag 3604 - Redirects output information to SSMS Results Pane
Trace Flag 3605 - Redirects output information to SQL Server Error Log: use if you need timestamps
You’ll see the above three Trace Flag are suffixed with least, more, and all. That’s because the output that each Trace Flag yields seems to have some overlap. And what’s more challenging is that I’ve found inconsistent documentation in older blogs that cover these Trace Flags as well. So I just opt to use them all to cover all of my bases.
-- Turn on Trace Flags
DBCC TRACEON(3604, 3004, 3014, 3213, -1);
GO
When turned on, you will receive a ton of diagnostic information after running a backup operation. Here’s an example (with prefix removed for brevity):
BACKUP DATABASE Sandbox_MultiFile_SingleVol TO
DISK='NUL'
WITH COPY_ONLY, FORMAT, INIT, STATS = 15
GO
--------------
[prefix]: BACKUP DATABASE started
[prefix]: Opening the database with S lock
[prefix]: Acquiring bulk-op lock on the database
[prefix]: Synchronizing with other operations on the database is complete
[prefix]: Opening the backup media set
[prefix]: The backup media set is open
Backup/Restore buffer configuration parameters
Memory limit: 32765 MB
BufferCount: 7
Sets Of Buffers: 1
MaxTransferSize: 1024 KB
Min MaxTransferSize: 64 KB
Total buffer space: 7 MB
Tabular data device count: 1
Fulltext data device count: 0
Filestream device count: 0
TXF device count: 0
Filesystem i/o alignment: 512
Media Buffer count: 7
Media Buffer size: 1024 KB
[prefix]: Preparing the media set for writing
[prefix]: The media set is ready for backup
[prefix]: Effective options: Checksum=0, Compression=0, Encryption=0, BufferCount=7, MaxTransferSize=1024 KB
[prefix]: Checkpoint LSN: 0:0:0
[prefix]: Checkpoint is complete (elapsed = 17 ms)
[prefix]: Start LSN: 3246:76679:230, SERepl LSN: 0:0:0
[prefix]: Last LSN: 3246:76775:1
[prefix]: Scanning allocation bitmaps
[prefix]: Data section: 204684263424 bytes in total
[prefix]: Scanning allocation bitmaps is complete
[prefix]: Do the first force checkpoint before copying data section
[prefix]: Checkpoint LSN: 3246:76679:230
[prefix]: Checkpoint is complete (elapsed = 8 ms)
[prefix]: Writing the leading metadata
Shared Backup BufferQ count: 7
[prefix]: Calculating expected size of total data
[prefix]: FID=1, ExpectedExtents=780610, IsDifferentialMapAccurate=1
[prefix]: FID=3, ExpectedExtents=781546, IsDifferentialMapAccurate=1
[prefix]: FID=4, ExpectedExtents=780523, IsDifferentialMapAccurate=1
[prefix]: FID=5, ExpectedExtents=780555, IsDifferentialMapAccurate=1
[prefix]: TotalSize=204684263424 bytes
[prefix]: Copying data files
[prefix]: Data file backup process set to run in serial mode within a volume.
[prefix]: Number of data file readers = 1
[prefix]: Calculating expected size of total data
[prefix]: FID=1, ExpectedExtents=780610, IsDifferentialMapAccurate=1
[prefix]: FID=3, ExpectedExtents=781546, IsDifferentialMapAccurate=1
[prefix]: FID=4, ExpectedExtents=780523, IsDifferentialMapAccurate=1
[prefix]: FID=5, ExpectedExtents=780555, IsDifferentialMapAccurate=1
[prefix]: TotalSize=204684263424 bytes
[prefix]: Do the second force checkpoint before copying diff section
[prefix]: Checkpoint LSN: 3246:76679:230
[prefix]: Checkpoint is complete (elapsed = 9 ms)
[prefix]: Start pin the log.
[prefix]: Start LSN: 3246:76778:1, SERepl LSN: 0:0:0
[prefix]: Offline the sparse bitmap
[prefix]: Scanning allocation bitmaps
[prefix]: Diff section: 3473408 bytes in total
[prefix]: Scanning allocation bitmaps is complete
[prefix]: Calculating expected size of total data
[prefix]: FID=1, ExpectedExtents=14, IsDifferentialMapAccurate=1
[prefix]: FID=3, ExpectedExtents=13, IsDifferentialMapAccurate=1
[prefix]: FID=4, ExpectedExtents=13, IsDifferentialMapAccurate=1
[prefix]: FID=5, ExpectedExtents=13, IsDifferentialMapAccurate=1
[prefix]: TotalSize=3473408 bytes
[prefix]: Copying data files
[prefix]: Data file backup process set to run in serial mode within a volume.
[prefix]: Number of data file readers = 1
[prefix]: InitialExpectedSize=3473408 bytes, FinalSize=3473408 bytes, ExcessMode=0
[prefix]: Calculating expected size of total data
[prefix]: FID=1, ExpectedExtents=14, IsDifferentialMapAccurate=1
[prefix]: FID=3, ExpectedExtents=13, IsDifferentialMapAccurate=1
[prefix]: FID=4, ExpectedExtents=13, IsDifferentialMapAccurate=1
[prefix]: FID=5, ExpectedExtents=13, IsDifferentialMapAccurate=1
[prefix]: TotalSize=3473408 bytes
[prefix]: Diff section copy finished
[prefix]: Last LSN: 3246:76781:1
[prefix]: Copying data files is complete
Processed 6244992 pages for database 'Sandbox_MultiFile_SingleVol', file 'Sandbox_MultiFile' on file 1.
Processed 6252472 pages for database 'Sandbox_MultiFile_SingleVol', file 'Sandbox_MultiFile2' on file 1.
Processed 6244288 pages for database 'Sandbox_MultiFile_SingleVol', file 'Sandbox_MultiFile3' on file 1.
Processed 6244544 pages for database 'Sandbox_MultiFile_SingleVol', file 'Sandbox_MultiFile4' on file 1.
[prefix]: Copying transaction log
[prefix]: MediaFamily(0): FID=2, VLFID=3246, DataStreamSize=65536 bytes
Processed 1 pages for database 'Sandbox_MultiFile_SingleVol', file 'Sandbox_MultiFile_log' on file 1.
[prefix]: Copying transaction log is complete
[prefix]: Writing the trailing metadata
[prefix]: Writing the end of backup set
[prefix]: Writing history records for NoteBackup
[prefix]: Writing history records for NoteBackup is complete (elapsed = 37 ms)
I’ve grouped together interesting “sub-operations” like when the tail of the log backup is taken. Note the multiple size estimates that are taken throughout as well. Note that there are 4 data files, which is why you see 4 FID entries each time. But also note that all 4 data files are on 1 single volume!
Key TF Output Highlights
Backup/Restore buffer configuration parameters
Memory limit: 32765 MB
BufferCount: 7
Sets Of Buffers: 1
MaxTransferSize: 1024 KB
Min MaxTransferSize: 64 KB
Total buffer space: 7 MB
Let’s compare and contrast this to a backup operation with multiple backup output targets (this different database’s data files are spread across 4 different data volumes).
BACKUP DATABASE [Sandbox_MultiFile_MultiVol] TO
DISK = '\\10.21.200.27\ayun-sql-backups\Sandbox_MultiFile_MultiVol_1.bak',
DISK = '\\10.21.200.28\ayun-sql-backups\Sandbox_MultiFile_MultiVol_2.bak',
DISK = '\\10.21.200.70\ayun-sql-backups\Sandbox_MultiFile_MultiVol_3.bak',
DISK = '\\10.21.200.71\ayun-sql-backups\Sandbox_MultiFile_MultiVol_4.bak',
DISK = '\\10.21.200.72\ayun-sql-backups\Sandbox_MultiFile_MultiVol_5.bak',
DISK = '\\10.21.200.73\ayun-sql-backups\Sandbox_MultiFile_MultiVol_6.bak',
DISK = '\\10.21.200.74\ayun-sql-backups\Sandbox_MultiFile_MultiVol_7.bak',
DISK = '\\10.21.200.75\ayun-sql-backups\Sandbox_MultiFile_MultiVol_8.bak'
WITH FORMAT, INIT, STATS = 10,
MAXTRANSFERSIZE = 2097152,
BUFFERCOUNT = 500, COMPRESSION;
GO
--------------
Backup/Restore buffer configuration parameters
Memory limit: 98295 MB
BufferCount: 500
Sets Of Buffers: 3
MaxTransferSize: 2048 KB
Min MaxTransferSize: 64 KB
Total buffer space: 3000 MB
Filesystem i/o alignment: 512
Media Buffer count: 500
Media Buffer size: 2048 KB
Encode Buffer count: 500
Backup(Sandbox_MultiFile_MultiVol): Number of data file readers = 4
I think there’s a lot of really cool data in here. Remember that you can use Trace Flag 3605 to log this information to the Error Log. Thusly, you could use that to record what your BACKUP jobs are currently doing and review them later at your leisure (just remember it turn the TF off, lest you bloat your logs).
If you want to see more examples of these Trace Flags in action, visit my GitHub and check out my demo scripts from the original presentation. I introduce the Trace Flags in the 1_Baselining.sql script, then leverage them throughout the other demo scripts.
Workers vs CPU Cores
One more thing to keep in mind are the total number of worker threads you have available on your SQL Server. That’s different than the number of CPU cores you happen to have. I’m not going to dive deeper into this one today but will leave this old but still valid blog from Bob Dorr for reference instead: “How It Works: How many databases can be backed up simultaneously?“
Bringing It All Together
Hopefully now, with the above information, you can see that you really need to do an analysis and essentially create a matrix, based on your requirements and available resources. This will help you determine how much you want to crank up your database tuneables to best accelerate your FULL backups for your environment.
Hope You’ve Enjoyed This Series
This’ll most likely be the final blog of this series, though I might do an “addendum” with random tidbits. Let me know in the comments if there’s anything else you’d like me to explore in an epilogue.
As part of my PASS Summit 2023 community session, I created a hybrid of two of my favorite sys.dm_io_virtual_file_stats scripts. It captures data from the DMV at two different intervals, to help you diagnose SQL Server I/O related performance data.
The inspiration for my particular session was to share knowledge about storage related performance headaches, to Andy-3-years-before, before I joined Pure Storage. I just celebrated my 2 year anniversary with Pure Storage, and to say that I’ve learned a tremendous amount about storage in these two years is an understatement. So this presentation was trying to address some of the more interesting performance & storage related nuances, beyond just looking at perf counters and DMV queries.
Scripts That I Love Using
That being said, in the course of the presentation, I did share two of my favorite existing scripts for working with sys.dm_io_virtual_file_stats.
So, I did what any good DBA would do with two useful scripts – I merged them together! (all done with prior permission from both Paul and Anthony.) And that’s why I’m writing this blog today – to highlight that it’s out there and for you to try it out if you want.
If you weren’t able to attend PASS Summit 2023, no worries – my slidedeck is also in the same github repository. But a slidedeck only tells part of a story, so I am looking out for opportunities to present this session virtually in the coming months!
Thanks for reading and let me know if you have any feedback the hybrid delta DMV the script.
Welcome to another edition of T-SQL Tuesday! This month’s blog party post is hosted by Matthew McGiffen. He asks bloggers to write about anything related to SQL Server Encryption and Data Protection.
Security Theater
I’ll start this blog off by saying that I despise “Security Theater. ”
If you’re not familiar with the term, it “is the practice of taking security measures that are considered to provide the feeling of improved security while doing little or nothing to achieve it.” Essentially it is doing something simply for the show of it, to make people feel better, while providing little to no actual security value.
And for us data professionals, especially on the operations side, security and data protection are topics that should be top of mind for all of us.
Transparent Data Encryption – Not a Fan
Of all of the various data protection options available to us in SQL Server, I argue that Transparent Data Encryption (aka TDE) is worthless Security Theater.
TDE encrypts your data files “at rest.” This means one cannot crack open a hex editor and just start reading your raw data. And did you know that you can use a hex editor and start reading string values right out of your MDF files? Go search on that – that’s a separate tangent you can go explore.
So Andy, what’s wrong with that?
I feel that TDE is worthless because it is meant to protect against relatively narrow attack vectors. One attack vector TDE is meant to address is if someone physically walks into your data center, grabs a hard drive, and walks out. Because your data files are encrypted-at-rest, they cannot then go home, hook up said hard drive to a PC, and read your data off of it.
But who stores their SQL Server data on singular spinning hard drives anymore? Okay, there may be some people that still use Direct Attached Storage (DAS) instead of a SAN, but those are few and far between. With a SAN, depending on how your data is laid out, it’ll most likely be distributed across a bunch of physical storage media. So you’d have to waltz out with an entire SAN chassis, as a singular drive would only contain fragments. And if people are waltzing out of your data centers with entire SANs, you have a much bigger problem already.
Fine, but Andy, if an intruder gets access to my Windows machine and copies the data files elsewhere, that’s still a problem that TDE solves, right?
Not so fast… if someone has access to your Windows OS, you’re already screwed. Why? Because then an attacker than very easily exfiltrate your Service Master Key from SQL Server. Once they have that, then can then use that key plus your copied data files and decrypt/open those data files on another SQL Server at their leisure.
I’m not going to link to the piece, but there is a piece out there that showcases all of this, with the exact script one needs. It’s really disgustingly easy.
And I haven’t even noted the trade-offs of TDE, like performance penalties and backup compression consequences.
Not a Sponsored Message – What about Pure?
I should note that all of the above is just my personal opinion. Yes I happen to work for a storage company now and TDE is especially pointless in my world. Why? Because Pure Storage ALREADY encrypts-at-rest all data that is written to our Direct Flash Modules!
The other reason why I dislike TDE, from a Pure Storage context, is that it also inhibits our storage array’s data reduction capabilities. If you’re writing encrypted randomized data down to a data-reducing array like FlashArray, there’s little that can be done with randomized data to data reduce or compress it – simple as that. So if your primary storage is a data reducing array like a FlashArray, you’ve just eliminated one of your primary cost savings… all for nothing.
What Should You Do Instead?
If you really need to have encrypted data, encrypt it WITHIN the application (like within SQL Server). Store your PII using column-level encryption methods. That has actual security value.
And if you are really concerned about security, you need to do a true threat assessment and figure out what attack vectors you want to protect from. Because after all, if someone is already on your Windows OS or physically in your data center, you’ve already failed hard at security and TDE isn’t going to save your butt.
Welcome back to Part 4 of my Backup Internals series. Today, I’d like to spend a little time exploring backup compression.
When you take a regular FULL BACKUP, SQL Server is literally taking a byte-for-byte copy of your data files. Don’t believe me? Then go read this, then come back. Additionally, Microsoft architected BACKUP operations such that the resource utilization and impact would be minimal (when using default parameters).
Back in the days of my youth, storage cost a heck of a lot more per megabyte (hahaha). And backups were extra copies of your data that had to live somewhere. So who would not want their backups to consume less (expensive) storage? But alas, Microsoft did not offer built-in BACKUP compression with SQL Server in its earlier days. Instead, data professionals had to resort to 3rd party products like Litespeed to have compressed backups. Investing in a software solution often outweighed the extra storage costs of an uncompressed backup, so it was a sensible expenditure. Unfortunately for backup software vendors, Microsoft introduced native backup compression in 2008.
Costs of Backup Compression
Regardless of how one does compression, it comes at a price. Compression reads and manipulates ALL OF YOUR DATA to make it smaller, which requires CPU and memory resources. The benefit is that SQL Server now has less data to send over the wire to your backup target, reducing required storage and (usually) overall execution time. And this (usually) made both DBAs and storage admins happy.
In our last two blog posts, we explored a BACKUP operation’s RAM and CPU worker thread utilization. But what happens when you turn on compression?
The answer for RAM and backup buffers is easy – compression requires 3x whatever backup buffers you were using already. So if a regular BACKUP operation needed 10MB of RAM for backup buffers, turning on compression will now use 30MB of RAM. The buffers themselves do not get larger, rather the number of “Sets of Buffers” goes from 1 to 3.
Digging Deeper: Compression and CPU Utilization
When utilizing compression, most of us know full well that SQL Server burns a lot more CPU. But how much CPU? Does it just burn more cycles on the same Reader & Writer threads that were invoked as normal? Or does it invoke additional threads to do compression work?
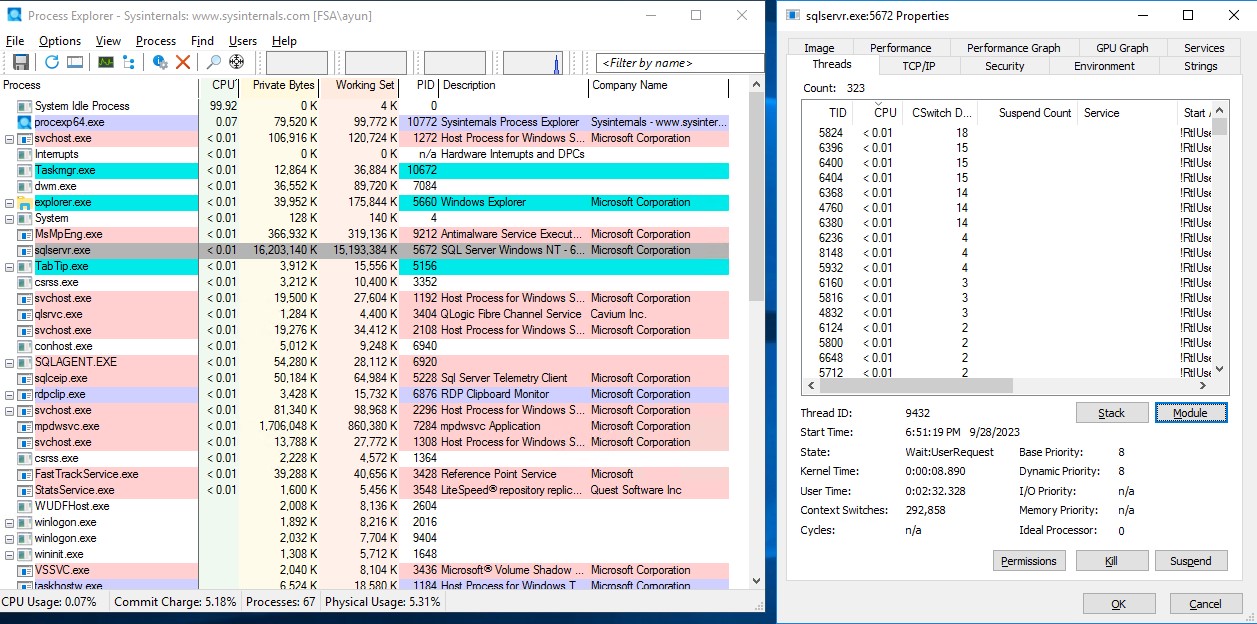
To dig a bit deeper, I turned to my good friend Sysinternals’ Process Explorer. If you’re not familiar with it, it’s essentially Task Explorer on steroids. One awesome thing you can do with it is right click a given process/.exe, go to Properties, and see Thread information!
Using this, I can at least see the number of threads that are actively using CPU at any given time. Here’s a baseline shot showing an otherwise idle SQL Server
Note that there are threads “using” CPU, but they’re all marked “< 0.01”, so for purposes of this simple analysis, we’ll consider them idle.
Next, this is what the output looks like when I execute a BACKUP operation, whose files are on a single volume, against a single backup target, with no compression:
Note that there are two threads (ThreadID or TID): 10636 & 5176, showing CPU utilization values that are not “< 0.01”. That’s indicative of my 1 Reader thread and 1 Writer threads for my BACKUP operation.
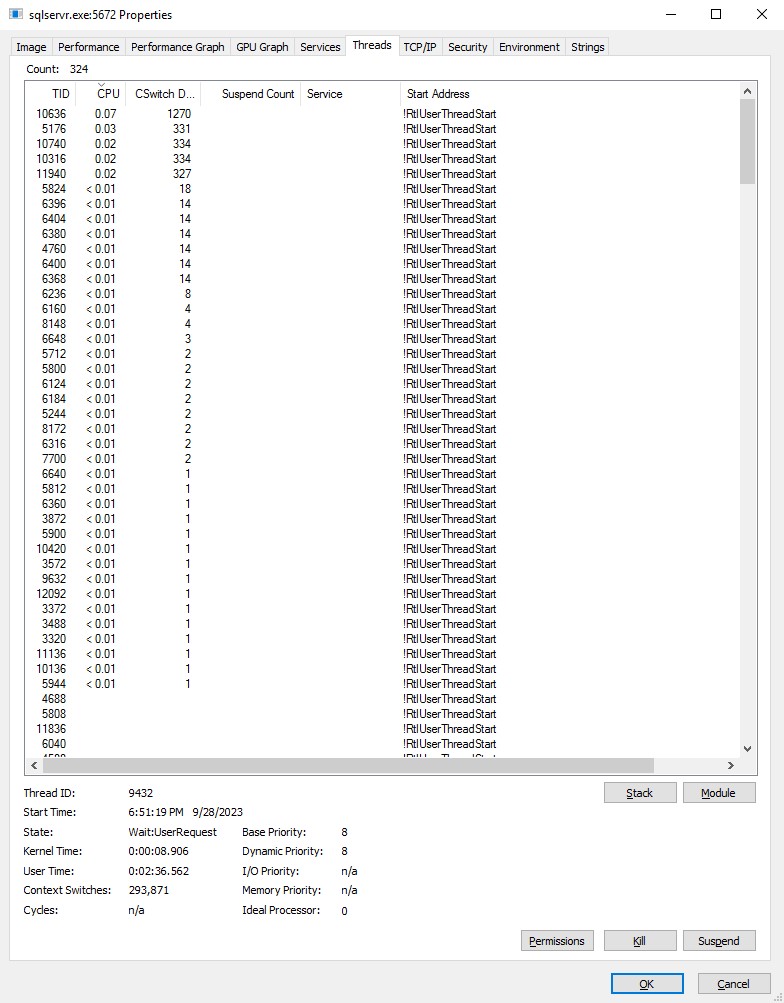
Now as a different control, I executed a BACKUP whose data files are on 4 separate volumes, against 1 backup target, with no compression.
Note here that I see activity on 5 threads: 4 reader threads and 1 writer thread.
Finally, here’s a BACKUP run with a single volume, single backup target, but with compression turned on.
That’s a heck of a bunch of threads that are not idle – over 20 in this screenshot!
How Many CPU Threads Does Compression Need?
I’ll come right out and say it; I’m not certain. Here’s the thing about the above observation methodology. It updates once per second and while it’s insightful, it’s not bulletproof.
For one, I cannot confirm with absolute certainty, that the given threads are related to the BACKUP operation. In fact, for my single volume, single backup target control, I’d occasionally get a sampling that would have a 3rd thread pop up with some activity, but only for a single snapshot. In multi-volume and/or multi-backup target examples, the number of threads active at any one time would occasionally drop below what I would expect. I attribute that to a CPU thread having to wait for a resource at that precise moment in time.
If I wanted to get deeper, I suspect I’d have to go attach a debugger to SQL Server and go digging to find the actual discrete calls that are invoking additional worker threads. But for the purposes of this blog, I’m content with the above observation that when using compression, many more CPU threads get spun up.
Compression: Yay or Nay?
As we’ve seen, Backup Compression requires more resources – CPU and memory. And unless someone else is willing to fill in the gaps, I cannot tell you the algorithm/methodology to better predict CPU thread utilization when it comes to utilizing Compression. But I would also argue that one should not let that deter you either.
In the end, everything is all about trade-offs… which is what Part 5 of this series will be all about – performance trade offs of using all of these different backup parameters.
Lately, I’ve been seeing a huge volume of Chinese LinkedIn profiles trying to connect with me. It’s quite obvious that these are fraudulent accounts, though they all have seemingly “real” profile information filled out. It’s been a nuisance at best… until earlier this month.
It’s Not a Matter of If… But When…
Earlier this month, I’d received a “New device registration for Remember me” e-mail from LinkedIn. But those e-mails get funneled to a separate folder that is rarely checked so I was totally oblivious to it.
A few days later, when I tried logging into LinkedIn, I got a strange “your account has been temporarily restricted” message and was asked to submit photos of physical ID. When I first encountered this, I thought I was getting phished! Switched browsers, VPNs, etc. and searched on the ‘net, and winds up that that part seemed legit. But I didn’t think about WHY it was happening (nor did the website actually say why), so I figured it was a routine thing and said screw it, I’ll deal with it later.
A few more days pass by and I finally start trying to deal with it. I submit my Driver’s License, and 30 seconds thereafter, I get an automated e-mail saying that my ID was rejected. Okay, now I’m getting pissed, because I’m effectively locked out of LinkedIn entirely.
While many out there wouldn’t shed any tears to never ever use LinkedIn again, I find that it has its uses, especially in my role and general community activity. So being locked out was definitely a bad thing.
Okay fine, so I try the ID verification again with my passport. But here’s where things get really obnoxious – I cannot submit ID again! The website returns an error saying that I’ve already submitted “recently” and to “wait before trying again.” Repeat this over 3 days and now I’m quite irate.
Digging Deeper
Digging deeper on Twitter and Reddit, I find others who have been hacked and hijacked by those lovely Chinese profiles. Even worse, I come to learn that LinkedIn Support is apparently swamped with a 2-3 WEEK response time… if you’re lucky!
So how does one open a Support Case with LinkedIn? You have to log in. But… I… CAN’T!!!
Reddit to the Rescue
I’d come close to resigning myself to waiting several weeks to MAYBE get my LinkedIn account back, when I stumble upon a peculiar Reddit thread. The poster shared that they were able to get their LinkedIn account resolution fast-tracked by… filing a complaint with the BBB.
Whuuut? Seriously?
I thought this was a fake post, but others chimed in claiming the same. I perused a few of the profiles & comment history of some of the individuals who claimed success, and they seemed like legit humans. Alright fine, what do I have to lose? So I filed a BBB complaint against LinkedIn with details and screenshots.
And I actually got a response within a few hours from LinkedIn!
Unfortunately it was a trash response, saying to check my Support Case correspondence. I “rejected the resolution” on the BBB, pointing out that the one cannot review a Support Case without logging in, and I couldn’t log in! A few hours later, I receive an automated Password Reset e-mail from LinkedIn!
Got My Account Back! But…
So yay, I got my account back! And upon logging in, the FIRST thing I did was enable MFA. I had thought I did so before, but obviously not.
And to my dismay and irritation, my entire profile had also been wiped. I was now “Cheryl,” a Chinese wedding dress maker out of Brooklyn, NY. Uhm… yeah, okay then.
So I’ve cleaned house and gotten profile back up and running. That was a few days of stressful irritation that I could have done without.
Epilogue
… but I think the hacker may be getting a bit of a last laugh. For whatever reason, all of my ads on LinkedIn are now in Chinese.